
E-charts
一款把数据转换动态的图表,支持多种图表样式。
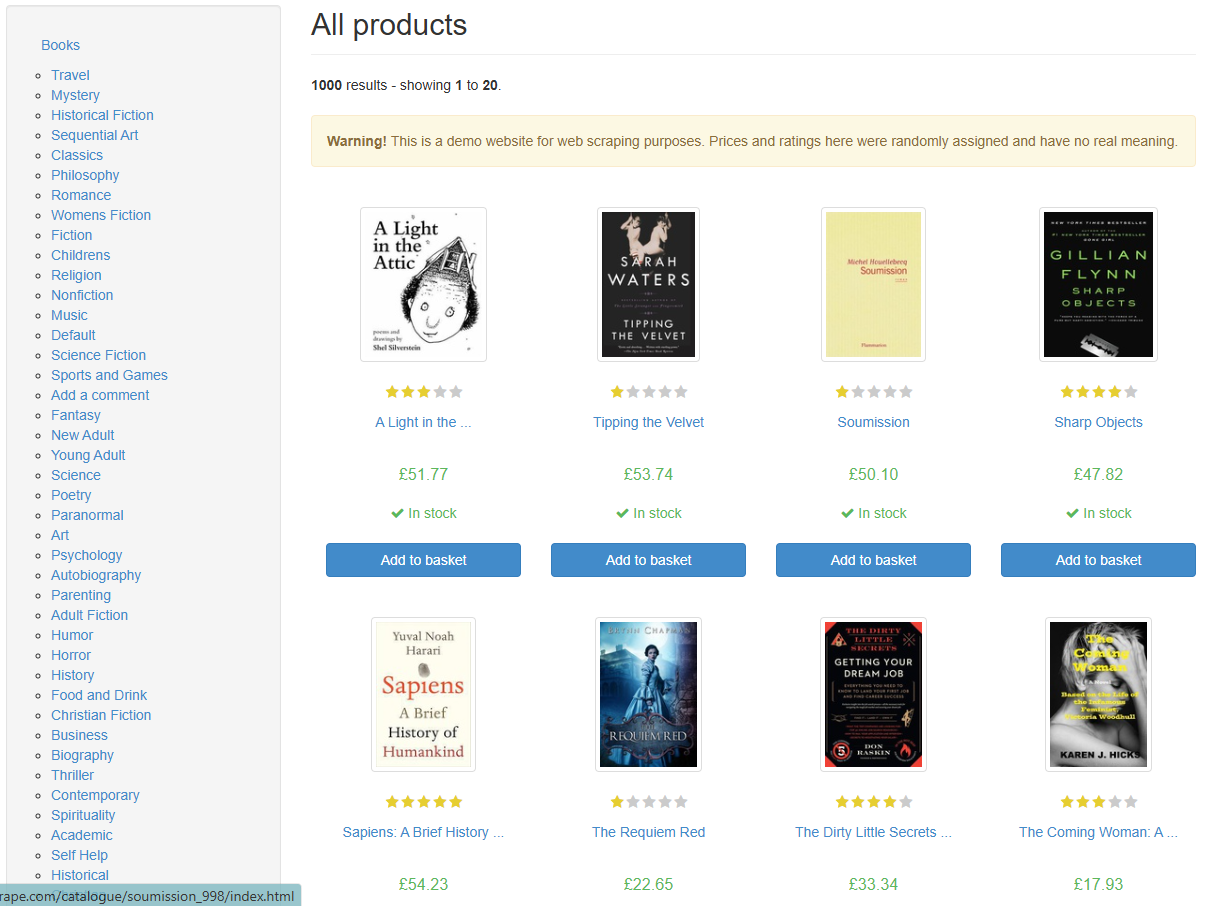
📝 这是一个专为网页爬虫学习者设计的免费练手网站,堪称爬虫领域的 “Hello World”。它模拟真实线上书店的结构,提供规范、稳定的静态 HTML 数据,允许开发者无风险地练习数据抓取,是 Python 爬虫教学中最经典的示范站点。
核心定位:这是一个专为网页爬虫学习者设计的免费练手网站,堪称爬虫领域的“Hello World”。它模拟真实线上书店的结构,提供规范、稳定的静态HTML数据,允许开发者无风险地练习数据抓取,是Python爬虫教学中最经典的示范站点。
该站点以“低门槛、结构化、可练手”为核心,完美适配入门到进阶的爬虫练习需求: 1. 三层清晰结构,覆盖完整爬取场景🏗️ 采用首页→分类页→详情页的经典电商层级设计。首页含全部分类导航,分类页展示分页图书列表,详情页提供单本书的完整信息(如UPC、价格、库存、描述等),可练习链接提取、分页遍历、多层级抓取等核心技能。 2. 标准化数据字段,易做解析练习📊 每页数据格式高度统一,包含书名、星级评分、价格(£)、库存状态、封面图等固定字段。详情页还提供税费、评价数等扩展信息,适合练习CSS选择器、XPath的精准定位,以及数据清洗与结构化存储(如CSV/JSON)。 3. 纯静态HTML,无反爬干扰🔓 不设置验证码、IP封锁、动态渲染等反爬机制,请求响应稳定。新手可专注于HTTP请求发送、页面解析、数据提取的核心逻辑,无需过早处理复杂的反爬策略。 4. 友好的“爬虫许可”✅ 站点明确作为学习沙箱存在,允许合法合规的抓取练习,避免了新手爬取真实网站可能带来的法律或道德风险。
| 练习难度 | 核心任务 | 适用技术 |
|---|---|---|
| 入门 | 提取单页书名、价格、评分 | Requests + BeautifulSoup/Xpath |
| 进阶 | 遍历所有分页,抓取全量图书 | 循环结构 + 分页URL构造 |
| 实战 | 按分类爬取并分类保存为CSV | 分类链接提取 + 文件IO |
| 框架 | 使用Scrapy爬虫框架整站抓取 | Scrapy(Spider、Item、Pipeline) |
总之,对于想要入门爬虫的开发者而言,这个站点是最理想的“第一站”。访问 https://books.toscrape.com/index.html,即可开启你的爬虫实战之旅!
「👉 查看最近更新的所有内容 」



